超短期预测性能更好!新疆大学研究者提出风电功率短期预测新方法
|
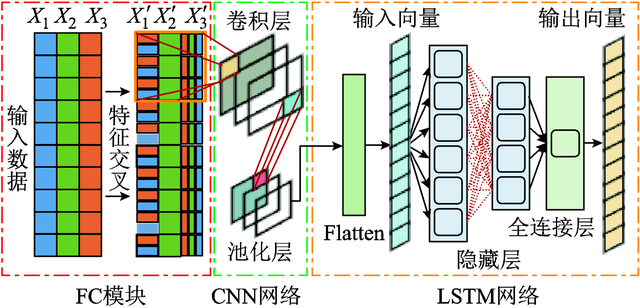
为提高短期风电功率预测精度,新疆大学电气工程学院的刘雨佳、樊艳芳、白雪岩、宋雨露、郝瑞鑫,在《电工技术学报》上撰文,首先在卷积神经网络(CNN)-长短期记忆(LSTM)网络模型的基础上,引入特征交叉(FC)机制,对风电场数据集进行相关性分析并交叉组合,增加特征维度,加强非线性特征学习,挖掘隐藏关联,提高训练精度,构建形成FC-CNN-LSTM预测模型。 研究者将该预测模型在风电预测中产生的误差值作为训练数据,训练生成误差补偿模型,利用该模型计算结果对风电预测数据进行补偿,进一步提高预测精度。仿真验证该方法具有较高的预测精度,且相比传统预测模型,在分钟级超短期尺度上的预测性能具有显著优势。 风力发电具有随机性、间歇性、不确定性等特点,且受限于成本、空间等因素,储能系统难以大量存储电能,导致弃风率常年居高不下。因此,精确的风力发电功率预测是提高可再生能源消纳、保障电网安全稳定运行的首要条件。 目前风电功率预测方法主要有物理建模、统计建模、人工智能算法建模三类。传统的物理、统计建模方法由于物理数据收集、参数选择难度较大,处理大量数据的能力较弱,难以建立精确的预测模型,所以在实际应用中通常采用人工智能算法对风功率预测进行建模。 早期采用的人工智能算法主要包括人工神经网络(ANN)、支持向量机(SVM)。人工神经网络虽然对非线性问题具有较强的处理能力,但其计算量与未知量数量成正比,容易陷入局部最优;支持向量机不易陷入局部最优,但其算法参数选择没有规律,需要使用者凭经验选择。 随着神经网络算法的不断发展,陆续有循环神经网络(RNN)、长短期记忆(LSTM)神经网络、门控循环(GRU)神经网络等序列数据预测的神经网络算法应用于风电功率预测。但是,相关对风功率预测的研究集中在对人工智能算法的使用和改进上,没有考虑数据中的不同特征与风电功率的相关性,以及特征表达关联性的能力差异,训练得到的模型只能建立单一、表面的关联,不能挖掘出更深层的关系,不利于风功率的短期预测。 新疆大学电气工程学院的研究人员,引入特征交叉机制对特征数据进行预处理,特征交叉也称为特征组合,是在计算机推荐算法领域广泛应用的特征处理方法,本质是利用原有特征之间的相互运算产生新特征。新特征除了可以增加特征维度,还因为包含了与待预测值之间的非线性关联,可以使模型学习到更为深层次的隐藏关系,增强模型拟合精度,得到更好的训练效果。
|